Our vision
Spending too much time on everything but data science is a huge pain point for data scientists. The growing model complexity gap is becoming a bigger issue every year. Our founders have worked together for years, innovating at the cutting edge of AI. They started Luminide to fill a void they have experienced in the field for 10 years.
Buckle up for an in-depth read, on this page we take you through the how and why behind Luminide!
Luke Hornof - Co-founder and CEO
Luke founded the software team at Nervana, an AI hardware startup which was acquired by Intel. As Director of AI Software at Intel, he grew his team to 150 engineers.

Anil Thomas - Co-founder and CTO
Anil was the third employee at Nervana. At Intel, he managed a team of research scientists who built innovative speech-recognition technology. He holds the title of grandmaster on Kaggle and was ranked #2 worldwide.

Introduction
The motivation for Luminide came from our own personal experience over the past 10 years, building technologies that span the entire AI hardware/software stack. We were two of the first employees at Nervana, an AI hardware accelerator startup, which was later acquired by Intel. We developed AI algorithms, frameworks before TensorFlow or Pytorch existed, compilers, GPU kernels, all the way down to drivers. We published numerous papers and were granted multiple patents. And we built AI models. Lots and lots of AI models, used across a wide variety of domains including oil and gas, underwater exploration, and agriculture. Anil even has Kaggle grandmaster status, indicating he’s one of the top model designers in the world.
During this time we used a lot of great tools for model development. Some of our favorites include PyTorch, Scikit, Jupyter notebooks, CuDNN, and GPUs. But there was one tool missing -- a simple, unified IDE for AI model development. This page motivates why such a tool is needed and how we are building it.
Data scientists should spend their time on data science
While building AI models, we were frustrated with all the time we were spending on everything but data science. This includes doing our own devOps -- downloading libraries, installing drivers, navigating complex dashboards, troubleshooting issues. And we repeated the same tedious tasks over and over while developing a model -- running numerous experiments, recording hyperparameters, tracking code changes, sifting through log files.
But we’ve been frustrated with all the time we were spending on everything but data science. This includes doing our own devOps -- downloading libraries, installing drivers, navigating complex dashboards, troubleshooting issues. And we found ourselves repeating the same tedious tasks while developing a model -- running numerous experiments, recording hyperparameters, tracking code changes, filtering through log files.
We heard the same complaints from data scientists around the world again and again. Given this demand, surely somebody would solve this problem. We anxiously awaited as new solutions were announced, but were always disappointed with what we found. After 10 years, we were still waiting.
There were two main reasons that contributed to these shortcomings:
No focus on model development. There were end-to-end platforms, one-size-fits-all solutions, or tools that addressed other aspects of the data science lifecycle. But by focusing on too much or other things, they didn’t solve the one thing we cared about most -- model development.
No integrated platform. There were lots of amazing tools and libraries out there -- code editors, notebooks, open-source libraries, and standalone tools. But getting the best of these required installing a variety of software, resolving dependencies, complex workflows to access GPUs or installing our own hardware and drivers, and then all of the system management that followed.
Model complexity gap
An even more daunting challenge facing data scientists is the model complexity gap. While hardware performance is following Moore’s law and doubles every 18 months, in that same time model complexity increases 35x. Cost estimates to train a large model such as GPT-3 range from $4.6-12M . And this gap will just continue to grow over time.
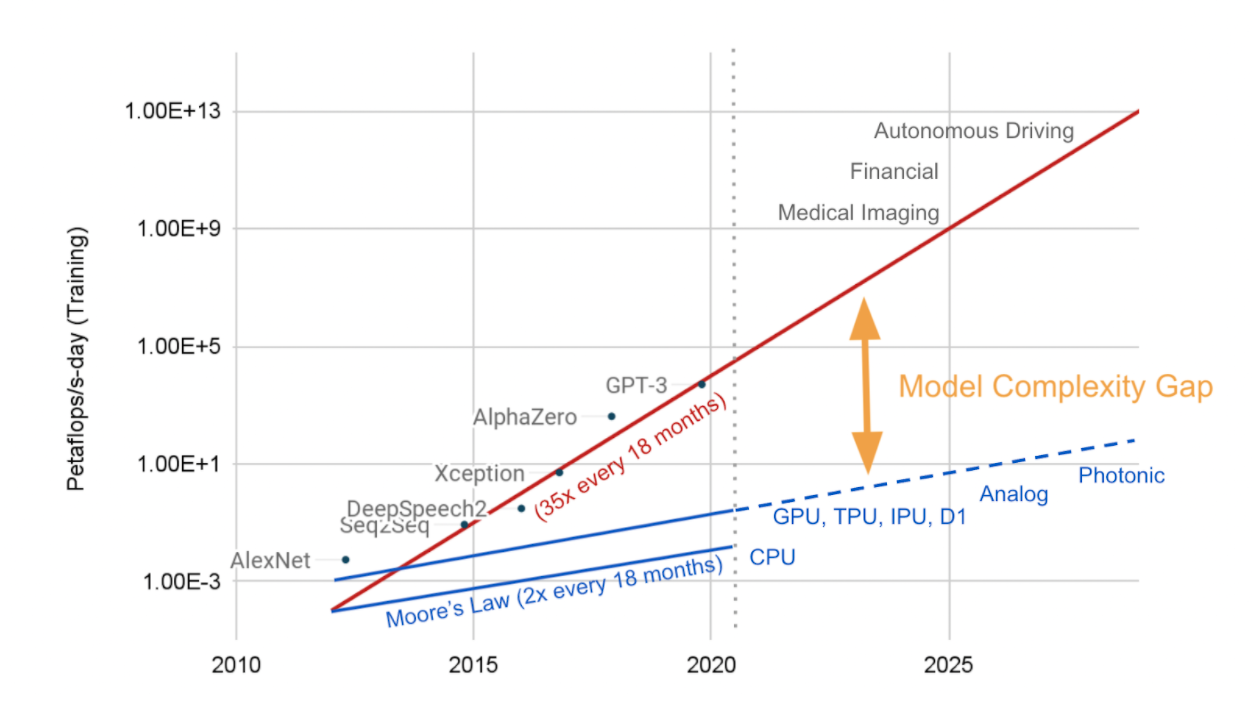
Simply scaling hardware won’t work because not only will it drive the price sky high, but it will result in an enormous carbon footprint. More computation requires more data movement, both of which consume more power, which in turn increases cooling costs. Studies show that training and tuning an NLP model emits over 78,000 pounds over carbon emissions, which is equivalent to 125 round trip flights between New York and Beijing. Another quote here about the cost.
Therefore, software solutions will be an essential piece to solving this puzzle. Or more specifically, well-coordinated efforts between software and hardware. The fundamental challenge is how to achieve the same model accuracy with significantly less computation. This will in turn save time and money, which is great for individuals and companies, and collectively will significantly reduce the overall world-wide carbon footprint.
Next-gen optimizations TODO: remove this, want it to look like an article
Our solution to closing the growing model complexity gap is software innovation. Hardware alone can't keep up. Our first ground-breaking innovation is the Luminide Early Ranking Engine.
Moore’s law only doubles every 18 months, model complexity increases 5 times every 18 months. Simply scaling hardware will drive the price sky high and create an enormous carbon footprint. Solving this gap requires software innovation.
Our ground-breaking Early Ranking Engine has been validated on real world problems to allow for 10 times faster training and 10 times less compute than the leading Bayesian optimizer. This feature has been built into our IDE for easy use on your toughest problems.
Our roadmap doesn't stop there. We have other optimizations in the pipeline to build the next generation of state of the art techniques (data augmentation, NAS, etc.). Due to our laser focus on model development and success to date we are confident in our ability to deliver. Stay tuned.
Get started
Start innovating today.
Explore the benefits of our IDE and get early access.
Meet the team behind Luminide's innovations.